
Voice To Help
Automate ticket creation with Voice To Help Snap-in. Identify and resolve customer issues from Google Play, Twitter, and Reddit data.
Created on 25th February 2024
•
Voice To Help
Automate ticket creation with Voice To Help Snap-in. Identify and resolve customer issues from Google Play, Twitter, and Reddit data.


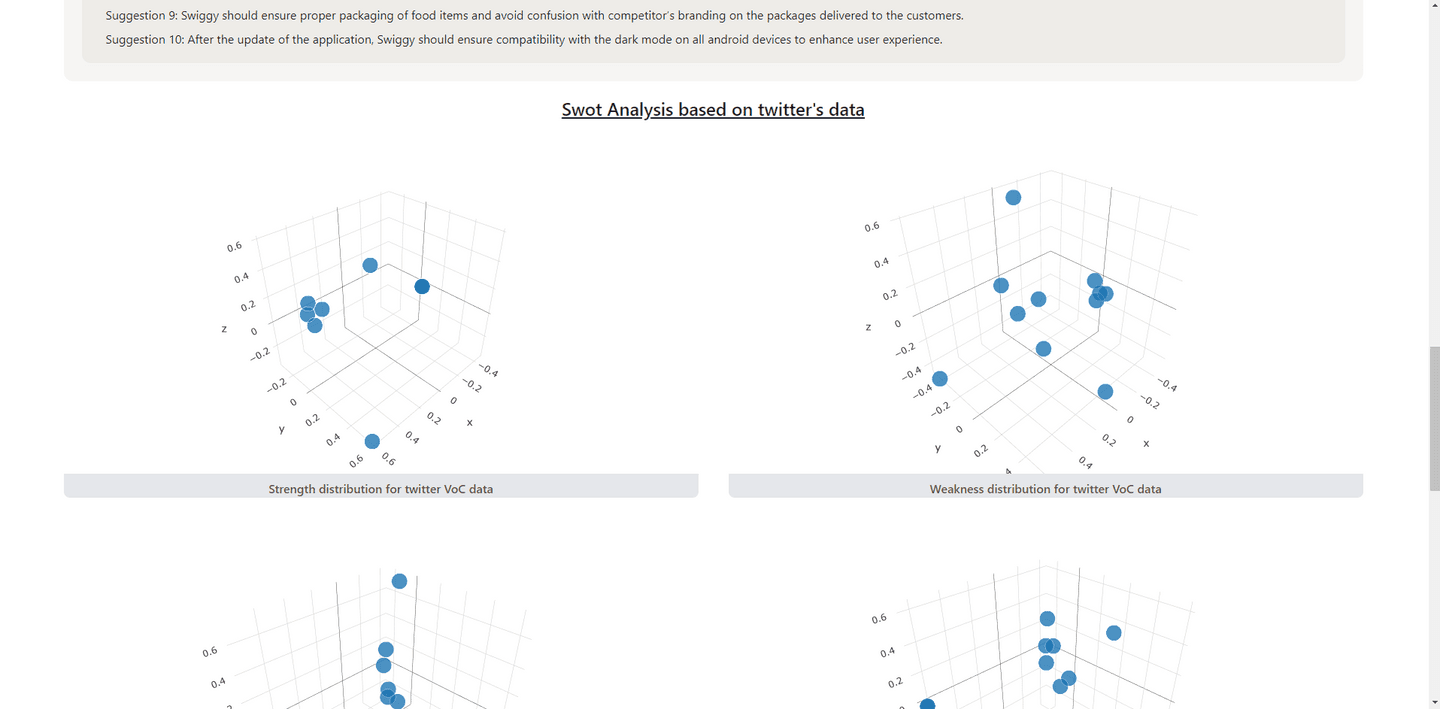
The problem Voice To Help solves
Voice To Help revolutionizes customer support, offering a multifaceted solution to enhance efficiency, streamline tasks, and elevate user experiences.
Unified Ticket Creation:
- Problem Identification: The Snap-in adeptly identifies customer problems across platforms, including Google Play, Twitter, and Reddit, facilitating swift ticket creation.
- Configuration: Users can seamlessly configure parameters such as company name, app ID, default part, owner ID, subreddit, GitHub details, Twitter handle, and hashtags through an intuitive interface.
Manifest File Structure: - Keyrings: Manages API keys for OpenAI securely, ensuring reliable functionality.
- Inputs: Customizable parameters, including company details, app ID, Twitter handle, hashtags to search for, reddit handle.
Intelligent Functions: - Data Collector: Automates the process of data collection. It runs every 6th hour to fetch latest data and generate insights from VoC data from different platform.
- Snap-in Intro: Provides a concise introduction to the Voice To Help Snap-in, enhancing user understanding.
- Insights Function: It exposes our dashboard url where user can check insights generated from VoC data.
- Google play review: It extracts review from Google play store based on user's input and generate ticket for the same.
- Twitter review: It extracts tweets from X based on user inputs and generate ticket for the same.
Automated ML Pipeline: - ML Model: Leverages machine learning to process Google Play reviews,tweets and data from reddit to extract meaningful insights, and clustering data for targeted improvements.
Challenges we ran into
Challenges Faced
-
Thinking about the Insights: Formulating a strategy for extracting meaningful insights from data sources such as Twitter, Google Play, and Reddit required careful consideration. We faced the challenge of designing an approach that could effectively analyze diverse data to provide valuable information and actionable insights.
-
Thinking about How to Cluster: Implementing a clustering mechanism presented its own set of challenges. Deciding on the appropriate clustering algorithms and methods to organize and categorize the data in a meaningful way required thoughtful consideration and experimentation.
-
How to Draw Inferences from the Cluster: Once the data was clustered, drawing meaningful inferences and conclusions from these clusters posed a significant challenge. Developing methods to interpret and extract valuable information from the clustered data required a deep understanding of the domain and iterative testing.
-
Handling Noise in the Data: Dealing with noise and outliers in the data proved to be a critical challenge. Implementing robust techniques to filter out irrelevant or erroneous data points was necessary to ensure the accuracy and reliability of the insights generated.
-
Scheduling Issues: Managing automated processes, especially when dealing with data from various sources,. Coordinating and optimizing the execution of tasks to ensure timely and accurate results required careful planning and implementation.
Addressing these challenges involved a combination of domain expertise, collaboration among team members, and iterative development processes. The solutions devised contribute to the robustness and effectiveness of our project in providing insightful analyses from diverse data streams.