Health-Sleuth
An ML model which investigates and predicts a person's risk of having diabetes, depression or hypertension.
Created on 13th December 2020
•
Health-Sleuth
An ML model which investigates and predicts a person's risk of having diabetes, depression or hypertension.

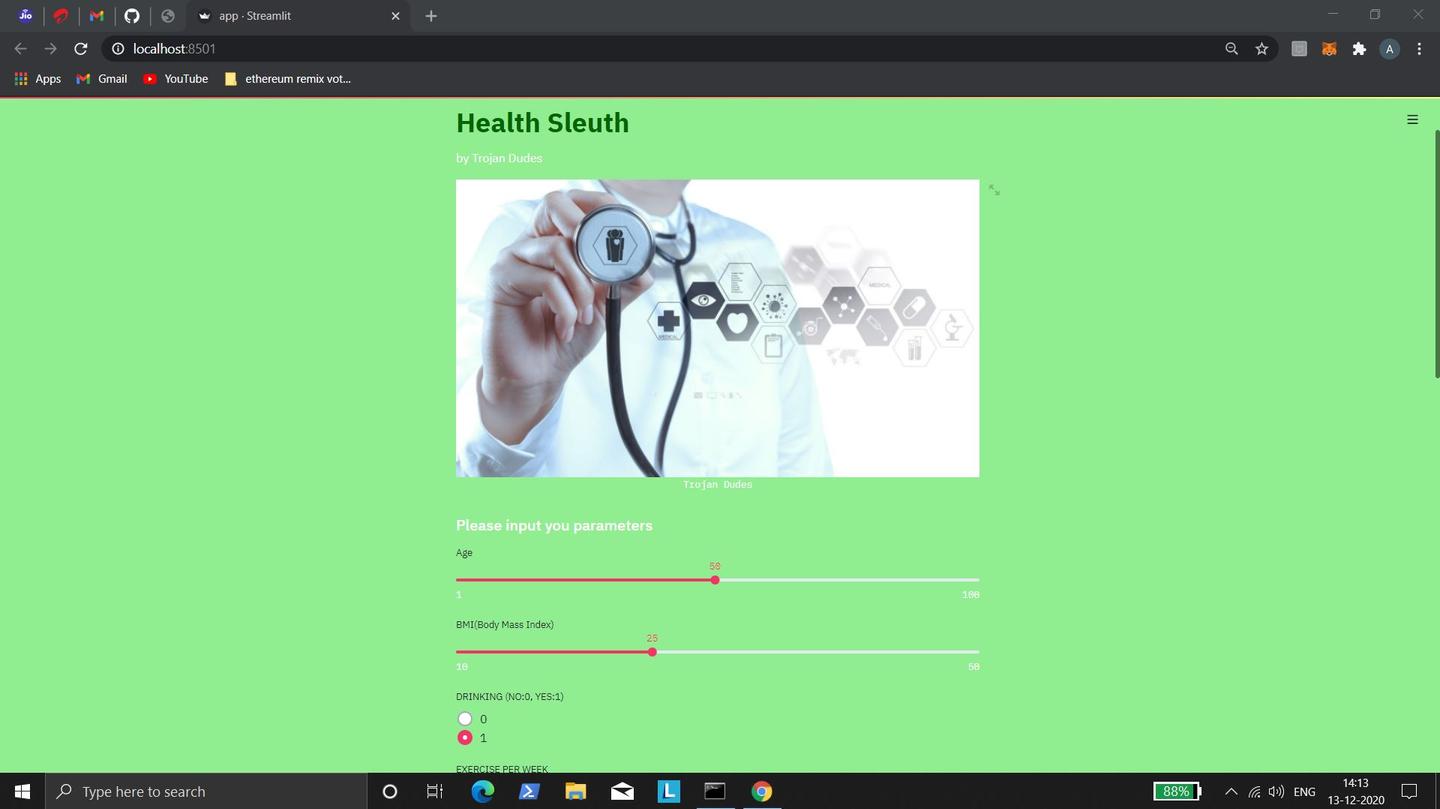
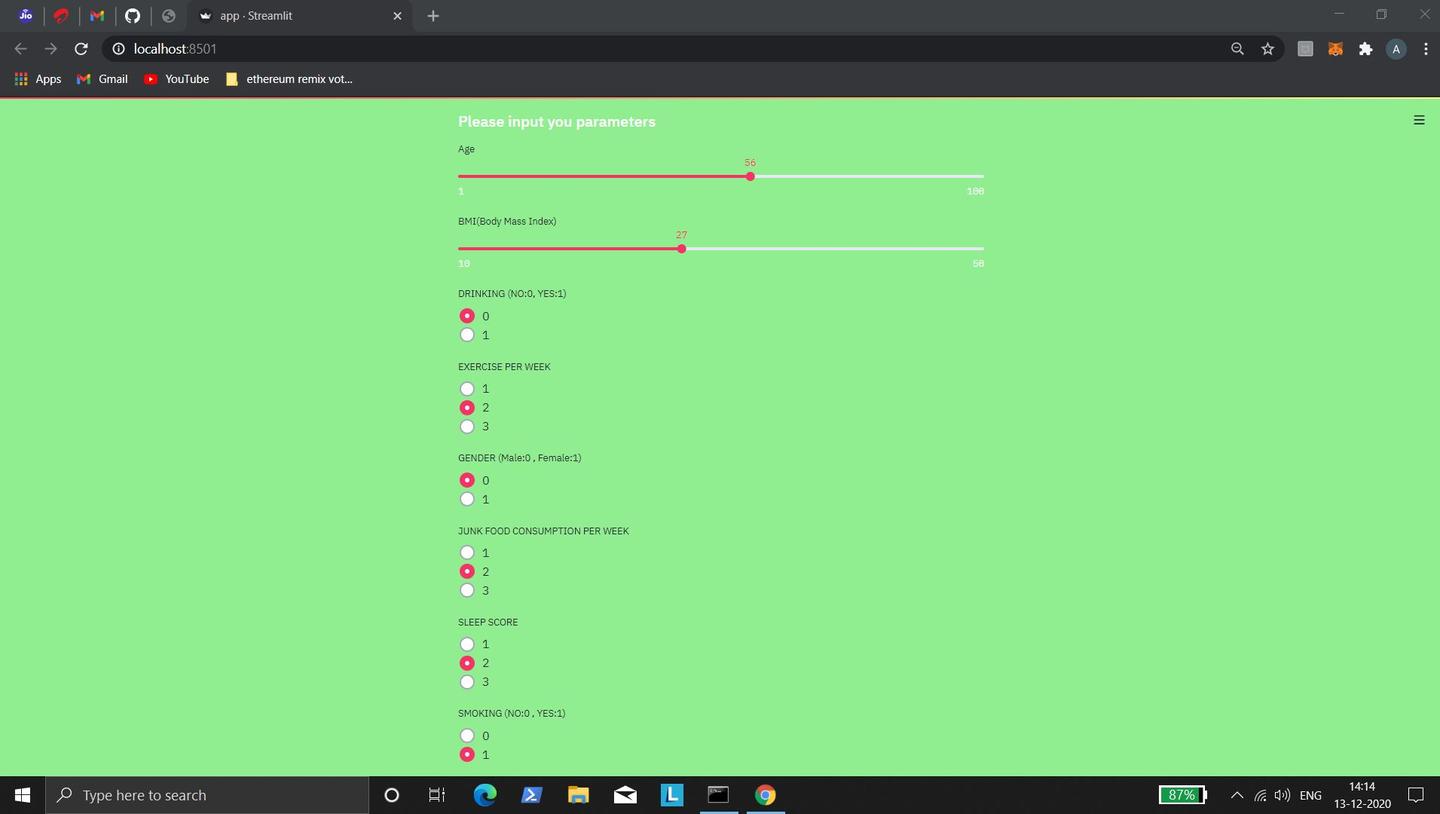
The problem Health-Sleuth solves
Diseases such as diabetes, depression and hypertension are a bit hard to diagnose properly. Take the example of hypertension,
your blood pressure could rise due to anxiety when you visit the doctor - this condition is known as whitecoat hypertension and it increases the chances of misdiagnosis. On the other hand, some people have masked hypertension. Depression affects one in three people with hypertension while one in four patients with diabetes have depression. It is estimated that one out of three adults have hypertension and that more than 50% of them are unaware of this condition. Our lifestyle has a lot of impact on these diseases. Baseline daily and non-daily smoking was associated with depression. Lack of physical activity and heavy alcohol drinking were associated with persistent depression. We wanted to create a project to conduct a health-investigation and diagnose a person with high or low risk of these diseases based on their lifestyle parameters.
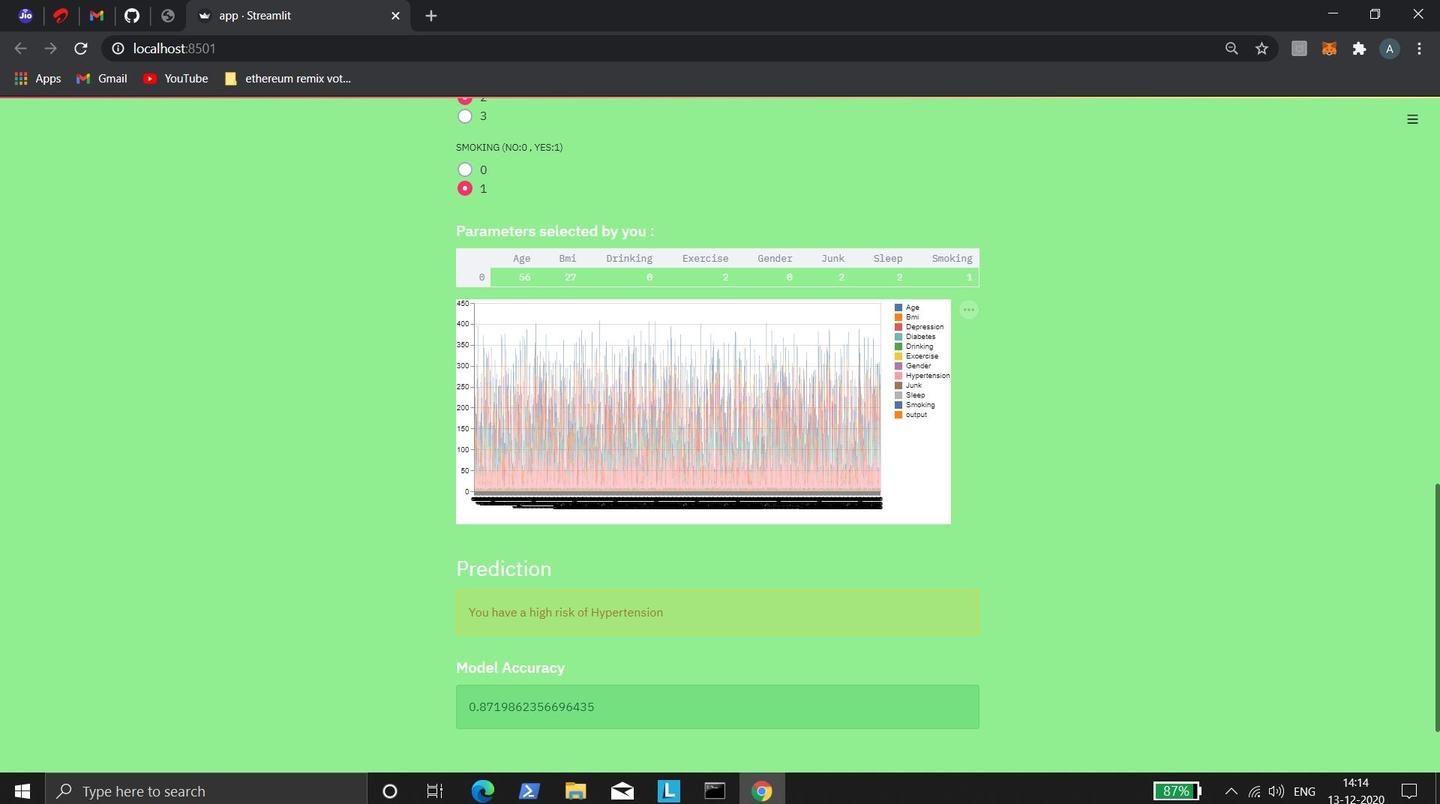
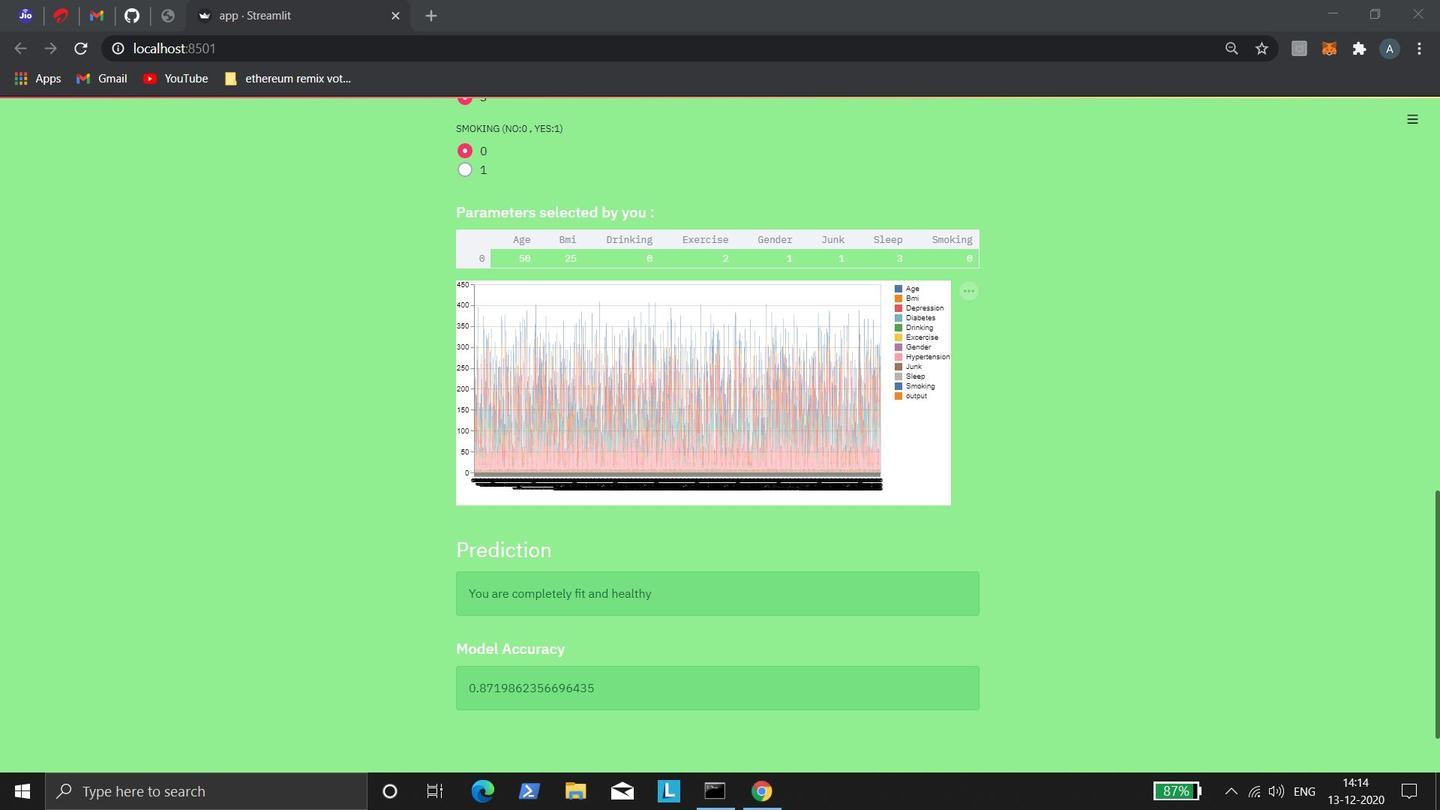
Health sleuth is essentially a disease-investigator which investigates about our health and risk to diabetes, depression and
hypertension. It is a machine learning model which takes in some clues from the user to conduct the investigation and can
predict whether a person has low or high risk of diabetes, depression and hypertension. Health Sleuth also predicts if a person
is completely healthy or not. Our model uses the Random Forest algorithm. We specifically chose the random forest algorithm for our model as it provided the highest model accuracy compared to the other algorithms we had tried out.
Challenges we ran into
We had some trouble finding an apt dataset for our idea but we were successful at last. We also had a problem of deciding the
algorithm to be used as we tried random forest regressor, decision tree regressor and linear regressor but we finally chose random forest regressor as it has the highest model accuracy. This was our very first time trying out ML and though we had hit some hurdles along the way, we were finally able to complete the project as intended.