
torch2circom
torch2circom is a tool for machine learning engineers to deploy machine learning models. It automatically generates circom code for your ML model, as it allows various operations.
Created on 3rd September 2023
•
torch2circom
torch2circom is a tool for machine learning engineers to deploy machine learning models. It automatically generates circom code for your ML model, as it allows various operations.


The problem torch2circom solves
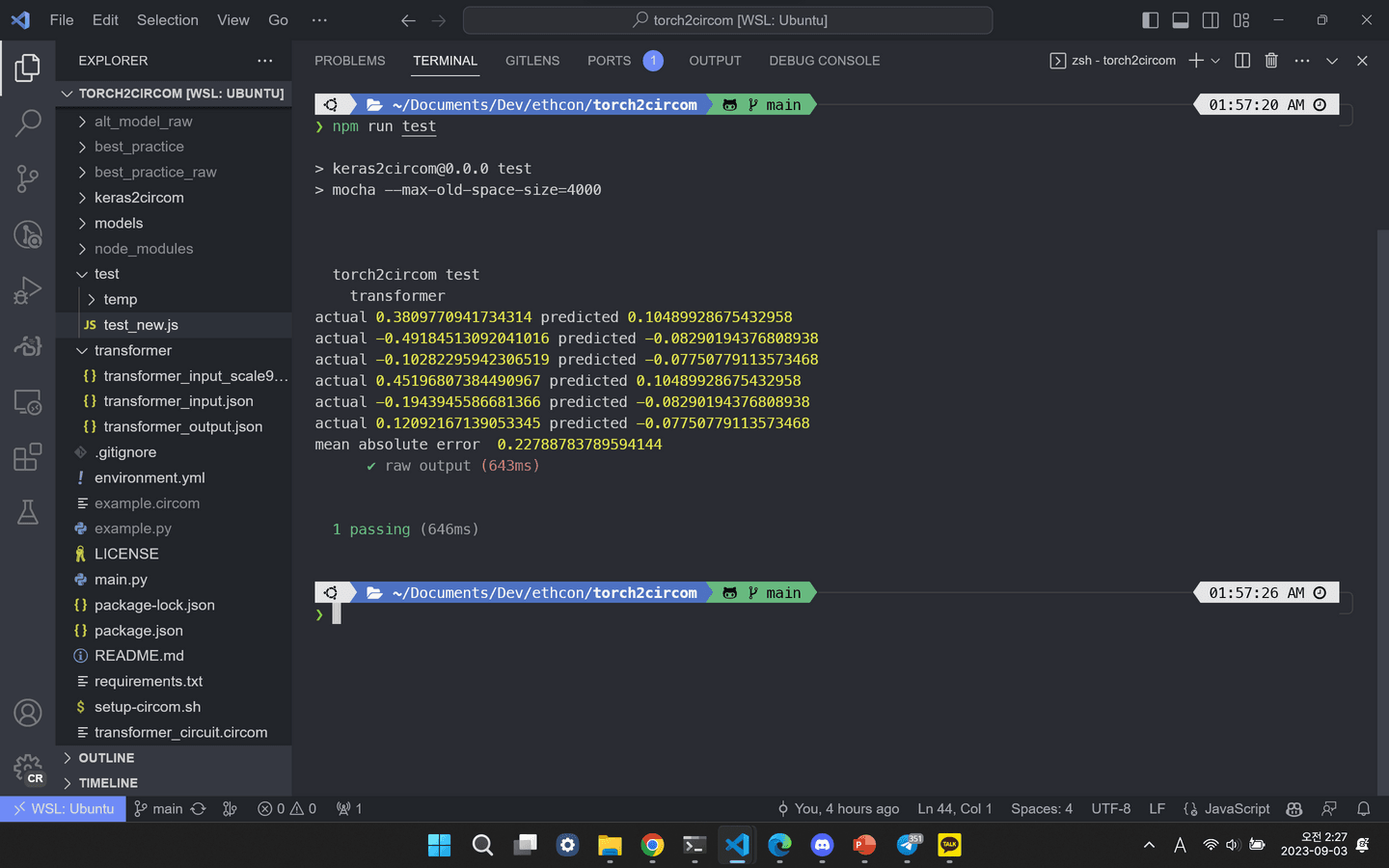
While the ZK community and ML community are both growing rapidly, there are few bridges connecting the two disciplines. One of them is ZK-ML, which validates correctness of ML by ZK. On ZK-ML, ZK can make sure whether data is actually used on running ML model. But the problem is applying ZK on ML requires some stiff backgrounds and principles if developed from scratch. Our goal is to minimalize the gap between existing ML technology and newly applied ZK technology: Therefore, we made a tool 'torch2circom', which bridges the gap. Developers can run torch2circom on their own ML model, as they acquires the proof generator written on circom. This can be utilized in smart contracts: When user submits an input, ML developer can give the result and the proof that they have ran the model. When the proof have been validated, the smart contract can be made so that users send money according to the validation.
Therefore, torch2circom is not only useful to ML developers who wants to prove their run to the users but also to the users to wants to ensure that their data has actually gone through a feasible neural networks.
Challenges we ran into
We report three challenges we ran into.
-
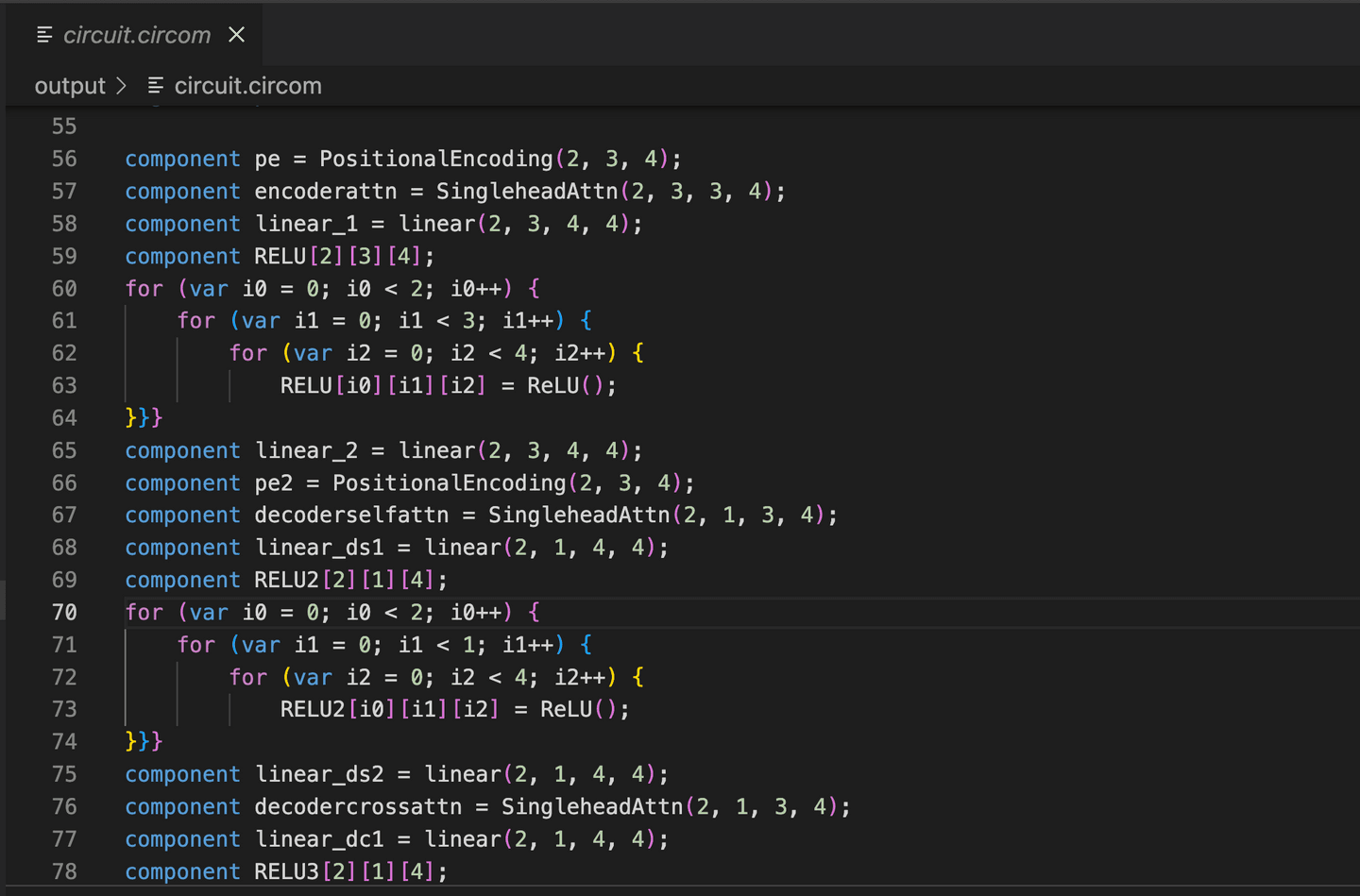
The original transformer architecture has the Softmax operation, which contains the computation of exponential functions. Therefore, we manipulated the transformer architecture so that all operations can be implemented realatively easily using the circom circuit. For example, we implement single-head attention instead of multi-head attention. We remove all Softmax due to exponential functions and layernorm due to its high computational cost. Yet, we note that these can be implemented using different normalization techniques where we leave this as future work.
-
While our automatic code generation roots on keras2circom code, due to substantial differences existing in pytorch and keras models, (pytorch models are realatively hard do analyize, where we have to both dynamically and statically check what operations are done.) We solved them by initializing the modules in the same order as their actual usage.
-
We were not able to find circom circuits for many of the operations we required. For example, we were not able to find circuit for batched matrix multiplication (B, N, d) * (B, d, M) --> (B, N, M). Therefore, we built our own circuits, including batched matrix multiplication, linear layers for batched input, and single-head self attention.
Tracks Applied (5)