CoronaXiv
CoronaXiv is an ElasticSearch-powered AI Search Engine that indexes the thousands of research papers that have piled up in response to the Corona Virus pandemic and illustrates various visualizations.
Created on 20th June 2020
•
CoronaXiv
CoronaXiv is an ElasticSearch-powered AI Search Engine that indexes the thousands of research papers that have piled up in response to the Corona Virus pandemic and illustrates various visualizations.

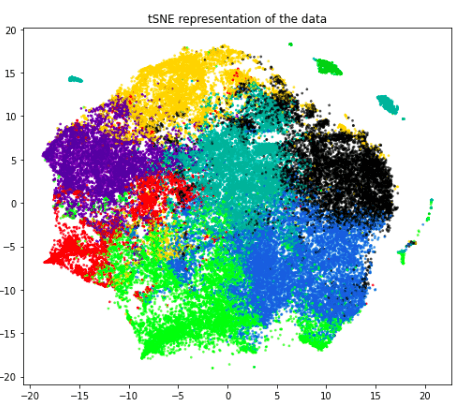
The problem CoronaXiv solves
A lot of researchers are working remotely across the globe, where lockdown restrictions are varying. Some researchers are working in labs, while some are working from home. In order to assist them in their endeavor to help defeat the Corona Virus pandemic, it would be really handy for any researcher to have a dedicated search-engine for Covid-19 papers, and also get links to other similar papers which are AI-recommended, so that it saves their time. Every second is precious in this battle against this global pandemic and hence, we have built CoronaXiv, an ElasticSearch-powered AI Search Engine for research papers related to the Corona Virus.
In the current scenario, one would perform Google search in order to look for some research papers. However, more often than not, certain keywords will yield results not related to the Corona Virus pandemic, and also lack UX since the user has to switch from one paper to another every time by going back to the home screen. With CoronaXiv, one can directly access the papers easily, with different visualizations to assist the user in understanding relations of different papers and identify papers based on keywords, or access papers clustered on basis of similar domains.
Challenges we ran into
None of us have experience with Elastic Search. It's really complex to understand if doing the non-GUI way. We also had to spend a lot of time pre-processing the CORD-19 Dataset available on Kaggle since the amount of useful content came down to almost 50% of the original dataset. Gathering data from external APIs was another challenge since those APIs were really slow. We faced issues with the deployment of the app on Azure, hence we had to step back and run the app on Heroku.
We went through the documentation of Elastic Search and tried to follow along. The pre-processing stage of the CORD-19 dataset took a long time but we finally extracted the useful information about each paper to be used and shown and also generated the embedding in order to assist the AI decisions. A trade-off was made on information retained due to PCA and the time constraint of running the model, where time constraint was given preference. The free-version of Elastic Search allows few results to be displayed. Hence, this is a drawback..