
TicketIn'site.AI
One-stop solution for comprehensive analysis of app reviews and user feedback from diverse sources, facilitating comparative trend analysis of various insight factors using AI.
Created on 25th February 2024
•
TicketIn'site.AI
One-stop solution for comprehensive analysis of app reviews and user feedback from diverse sources, facilitating comparative trend analysis of various insight factors using AI.

The problem TicketIn'site.AI solves
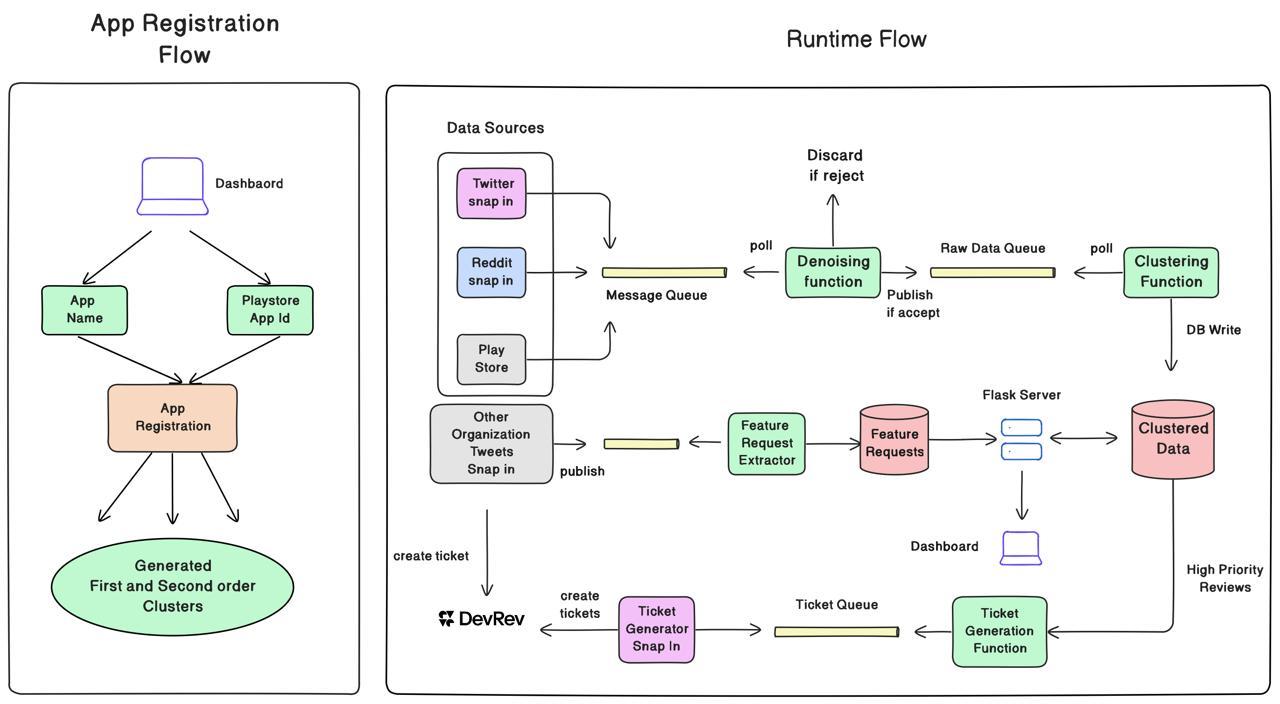
- Develop the solution in a modular and scalable way by decoupling the different services. Dependency between services is reduced.
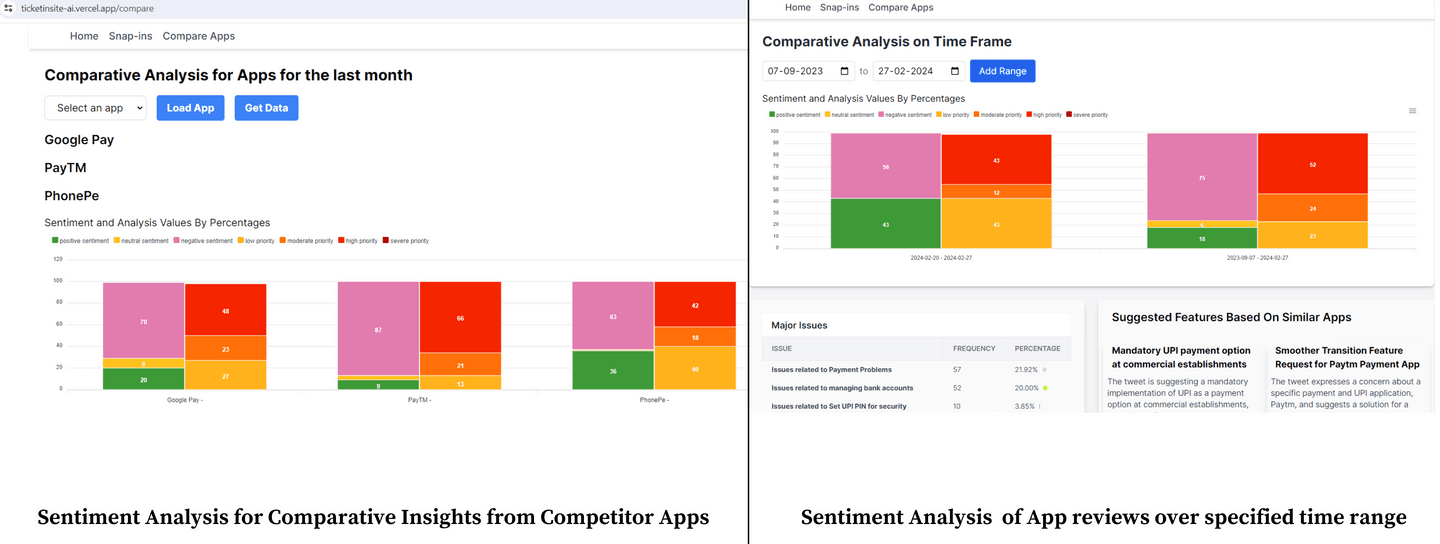
- Comparative analysis of competitor apps under the same category which can be used to predict feature requests in the future.
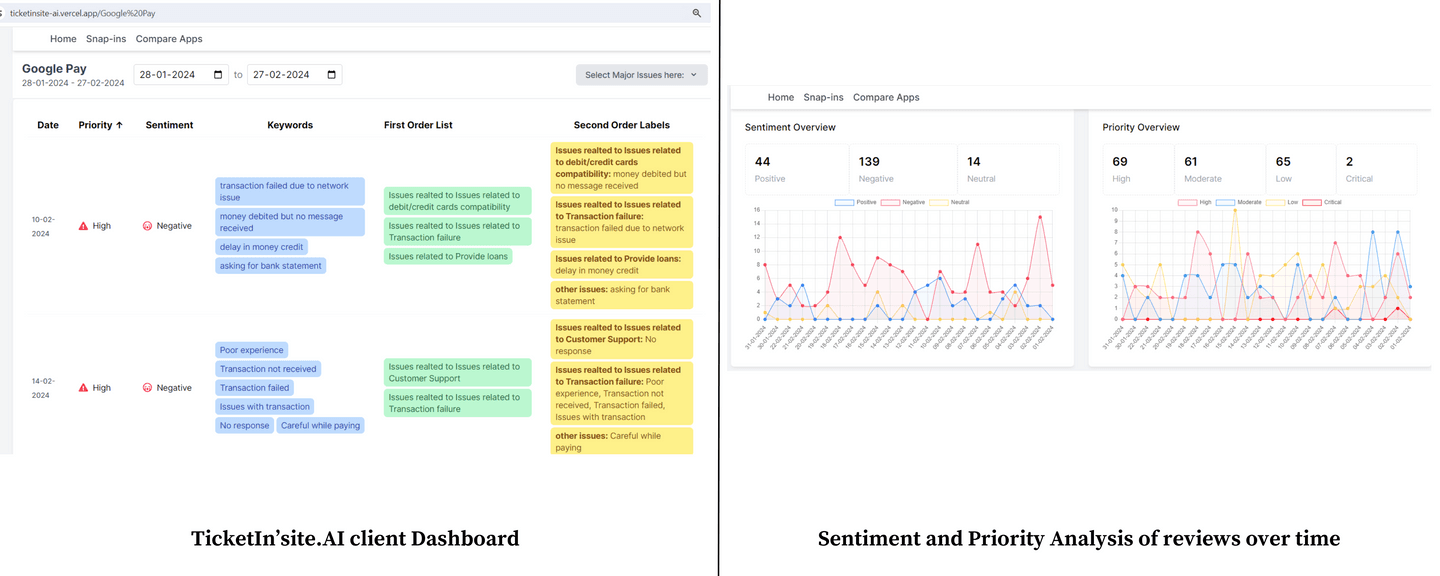
- Create a priority list of issues (critical to low).
- Measuring general customer sentiment over time (especially after product launch/version update).
- Analyzing pricing (subscription/in-app purchase) sentiments.
- Identifies positive keywords from ‘most-relevant’ reviews which can be used for SEO optimization.
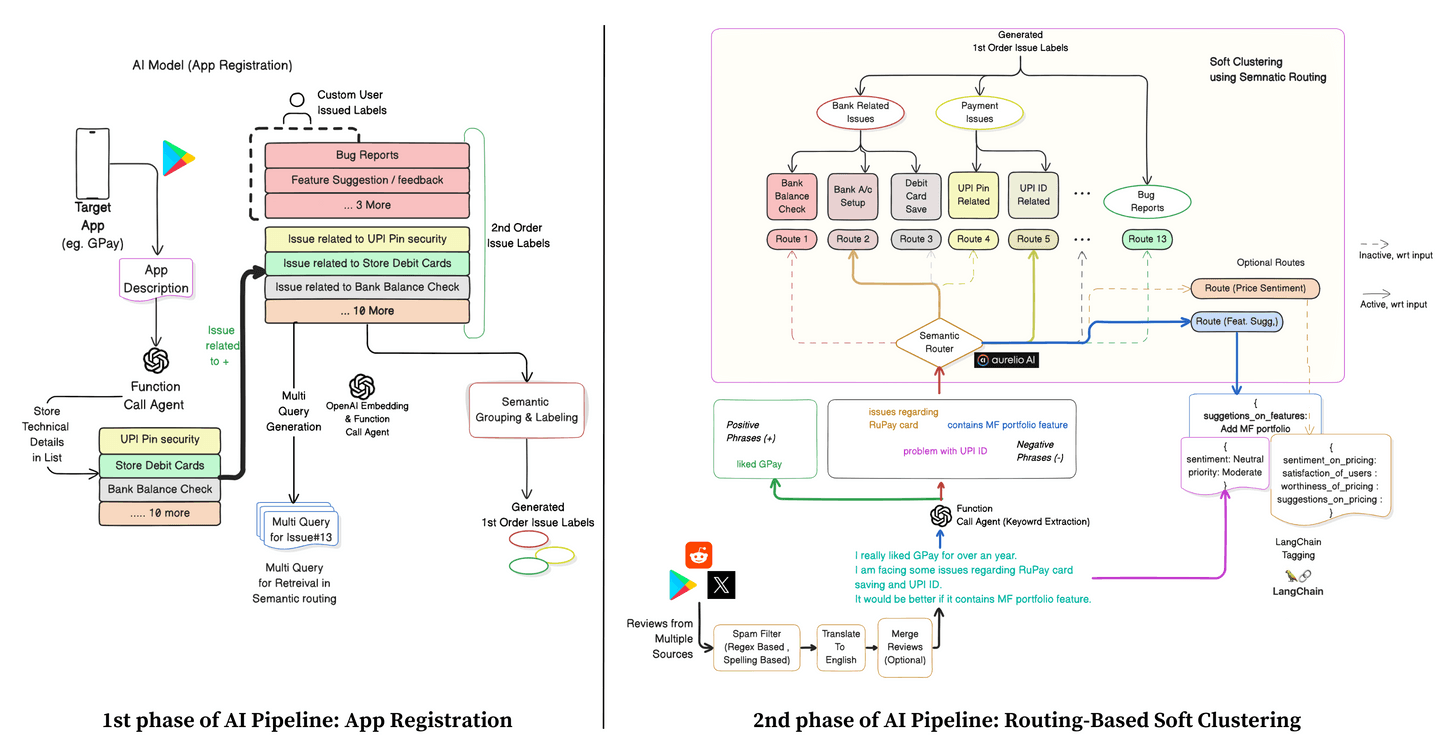
Because of the modular nature, any service breaking will not take down the entire system, there will be no loss of data. Since we are following a bottom-up approach of clustering, for each issue label we provide key-phrases due to which it is assigned so. It brings an aspect of causality-implication which mitigates the main safety issue of non-explainability in LLMs.
Challenges we ran into
-
Challenge 1: Being dependent on high-temperature LLMs and large prompts, the chances of LLM hallucination are very high.
Solution: Since our issue labels can be both AI-generated and user-defined, we can have as many labels, routes, and tagging chains. But as we are not using high-temperature LLMs, the hallucination problem is greatly mitigated. Hence, there is no need to change the prompts to handle different types of app categories. -
Challenge 2: If any review contains multiple different negative aspects, we can’t capture them all even if we use heavy prompt engineering.
Solution: We break down the whole review into multiple different phrases, followed by routing them to different routes simultaneously. Hence, each review is labeled with multiple "2nd Order Issue Labels," achieving the aspect of soft clustering. This two-step process helps in better performance and accuracy. -
Challenge 3: Making the system decoupled and scalable was difficult as there were multiple moving pieces, doing different things. Also, while setting up multiple snap-ins with varied functionality, sometimes the API response was malformed, with having to redeploy the snap-in for each bug fix.
Solution: We solved this by using message queues and creating the system so that each part of the system can be independently scaled. Multi-snap-in issues were solved with time spent debugging and utilizing the snap-in logs.