
INFOX
SaaS that allows customers to voice-over using model made by voice actor by purchasing NFTs issued by them. To access the model, we intend to use NFT as an api key.
Created on 6th August 2022
•
INFOX
SaaS that allows customers to voice-over using model made by voice actor by purchasing NFTs issued by them. To access the model, we intend to use NFT as an api key.

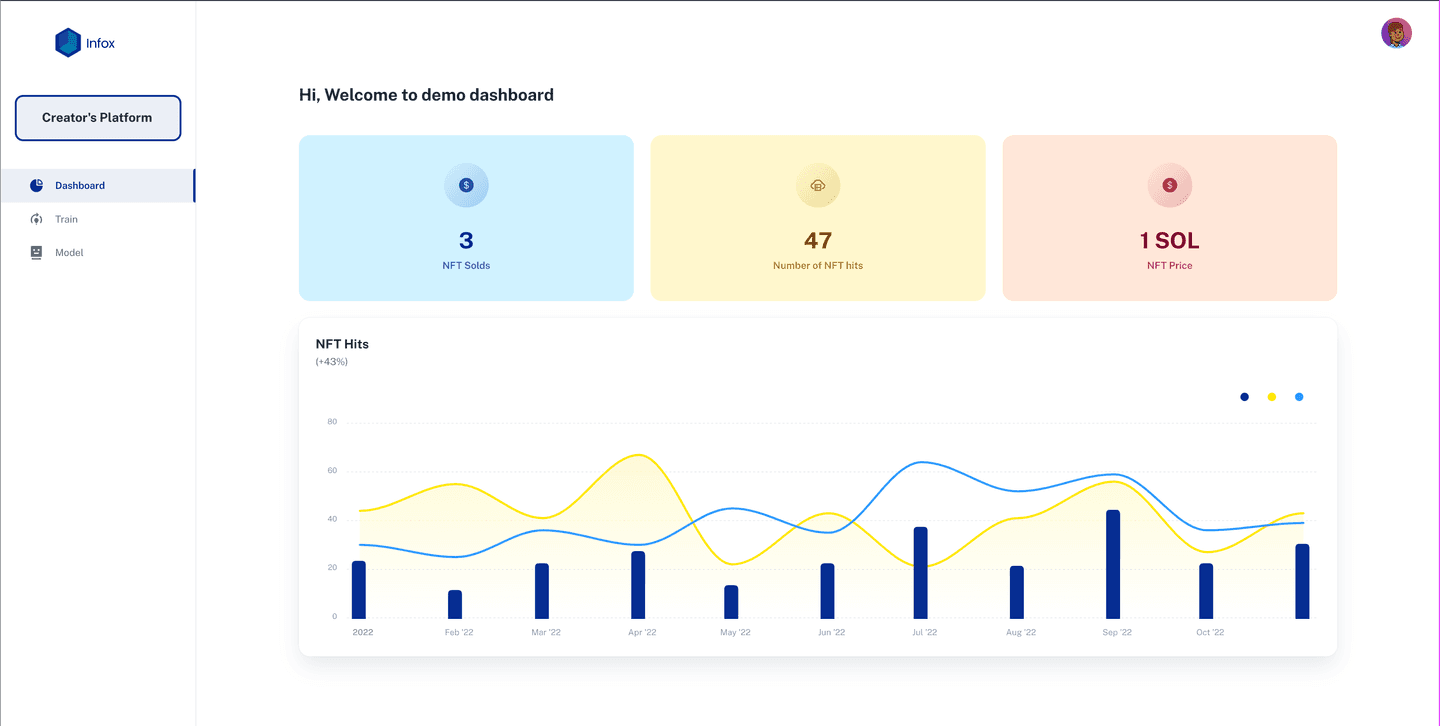
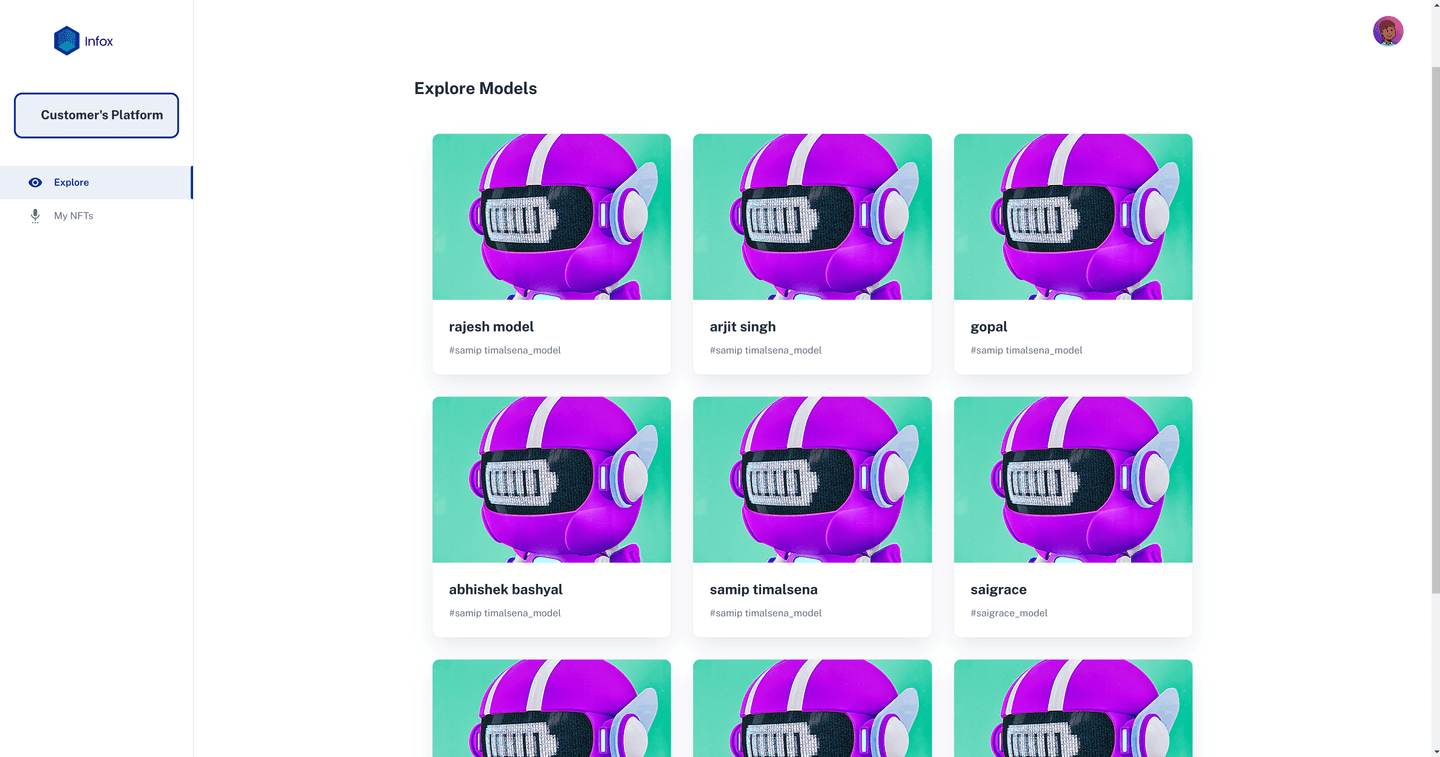
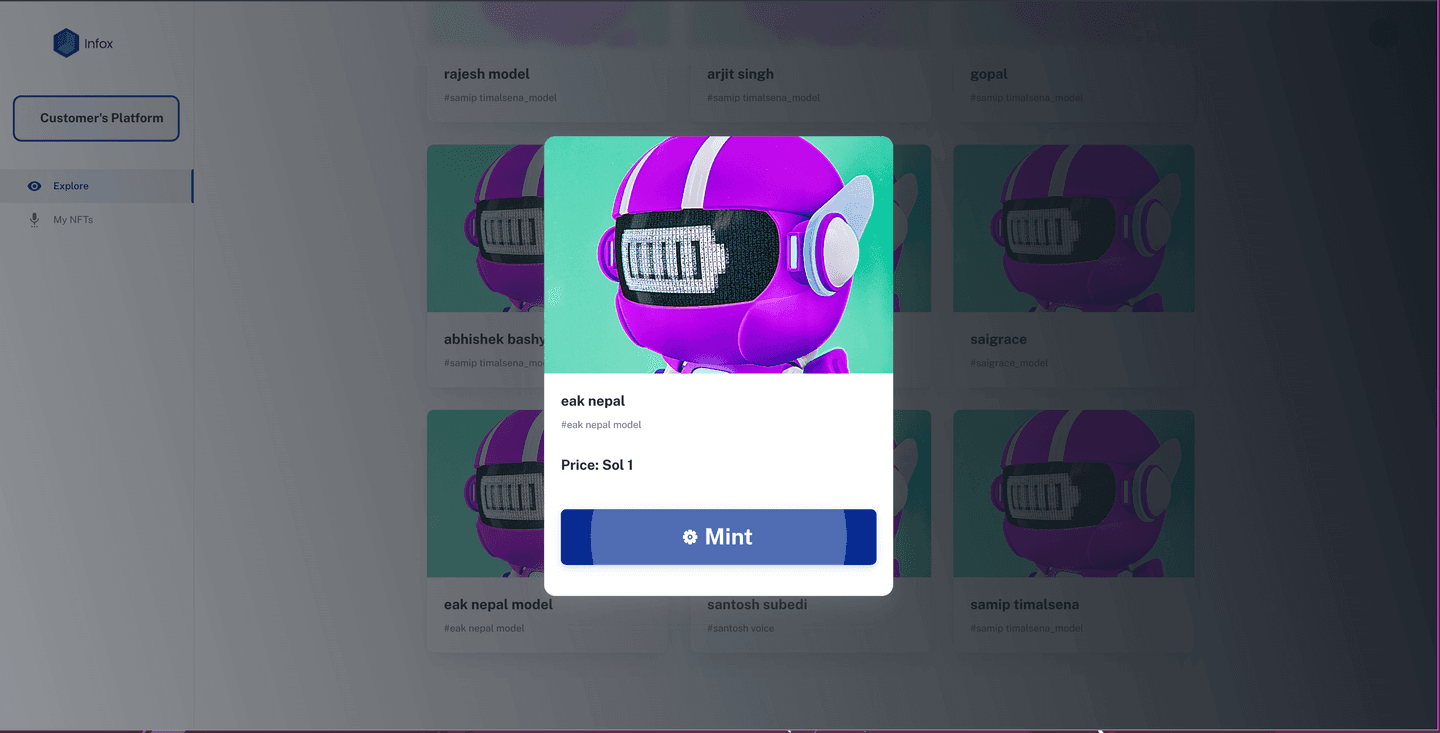
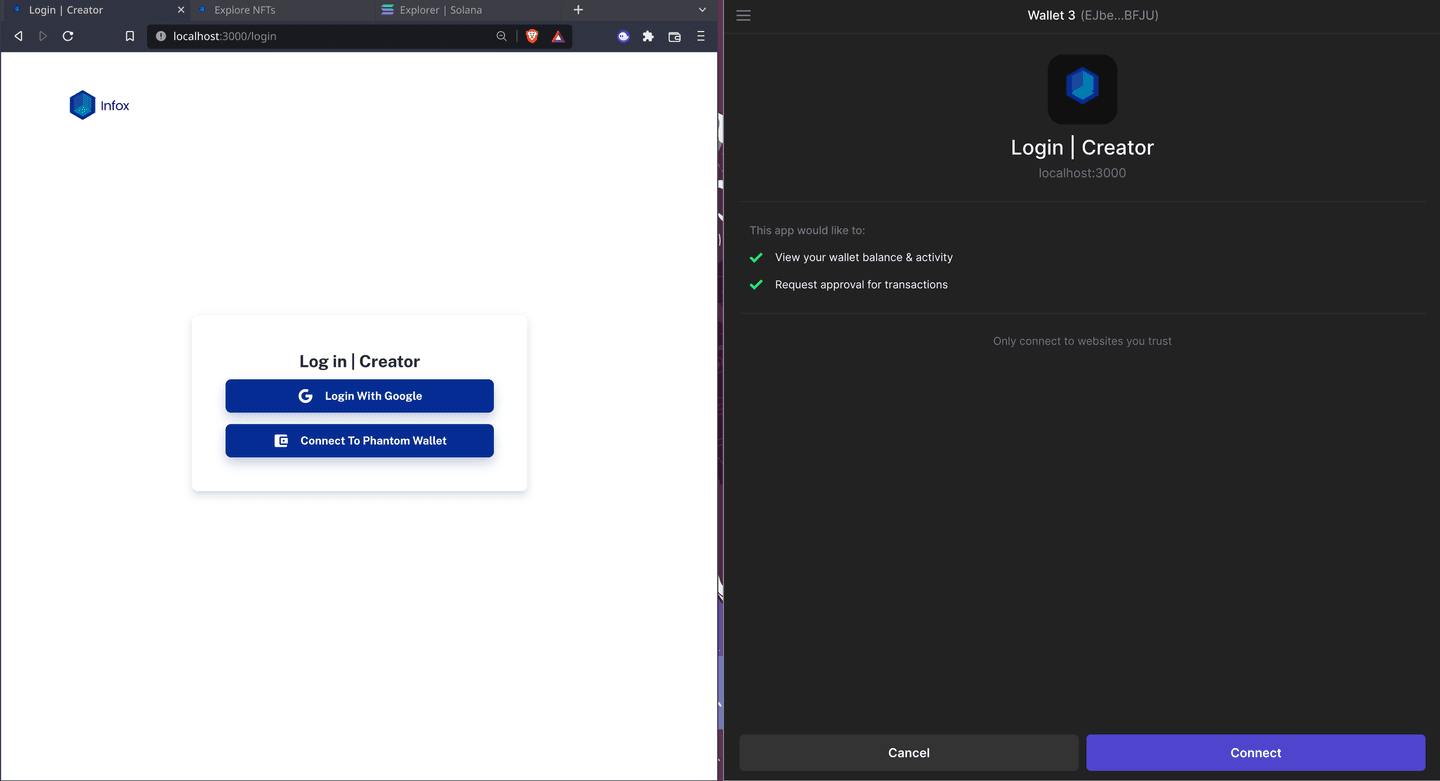
The problem INFOX solves
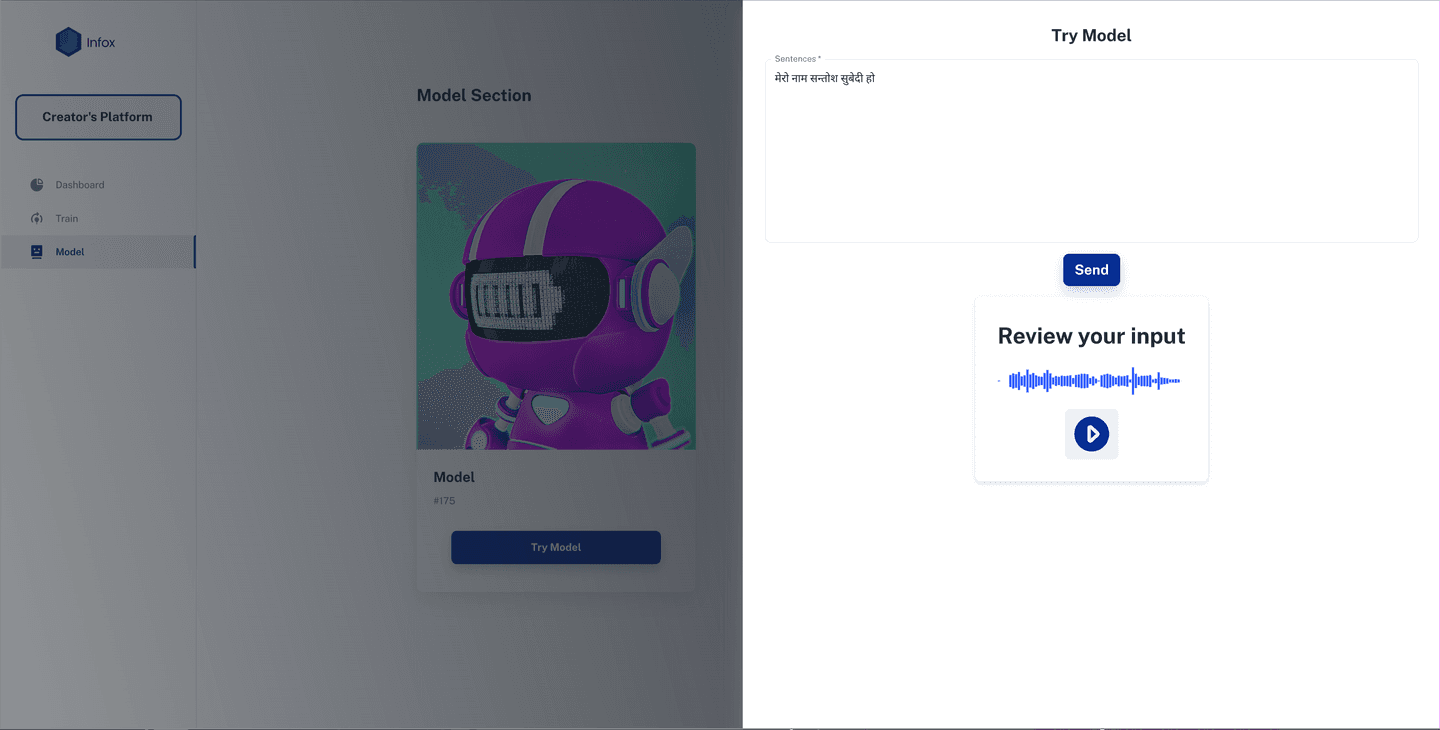
There are two problems that we thought to solve using our SaaS. The first problem is faced by an actor/actress who plays a movie in a different language other than their native tongue. The option they have is to either learn the language or ask the production team to dub the script by a fluent speaker. This is where our product shines. The actor/actress can record their voices in their native language on our platform creating a dataset for the model. After the training completes, the model can be used to produce their voices in different other languages. The text in other languages is transliterated to the Nepali language and fed into the model to create the output voice.
The other problem is for a category of user who wants to voice-over in a renowned voice artist’s voice. To make this easier, the artist trains their voice model and releases its NFTs. The user can purchase the NFT to use the model for voice-over in different languages.
Challenges we ran into
We faced challenges in multiple steps during the product development. Firstly, to train a base model we had no datasets and pre-trained models publicly available. Overcoming this challenge was the most difficult and time-consuming. We had to create our own dataset. We surfed on youtube to find a video with clear audio in Nepali language. Finally, we found a channel with audio books in nepali. We clipped an hour audio clip and splitted it in silence. Using an open-source speech2text model we transcribed the audio and manually validated the annotation.
The resource constraints was another problem we encountered. The free GPU quota of Colab and Kaggle was a little insufficient for the model to be trained to produce an excellent output. Similarly, though the scripts for model training are available as a service in our product, we can’t start it due to limitation of our resources.
Also, all of us were new to the Solana ecosystem so it took us a while to get around the concept of solana account and PDA model.