
FinanceGPT
Ask it anything about any company and it will answer!
Created on 25th March 2023
•
FinanceGPT
Ask it anything about any company and it will answer!

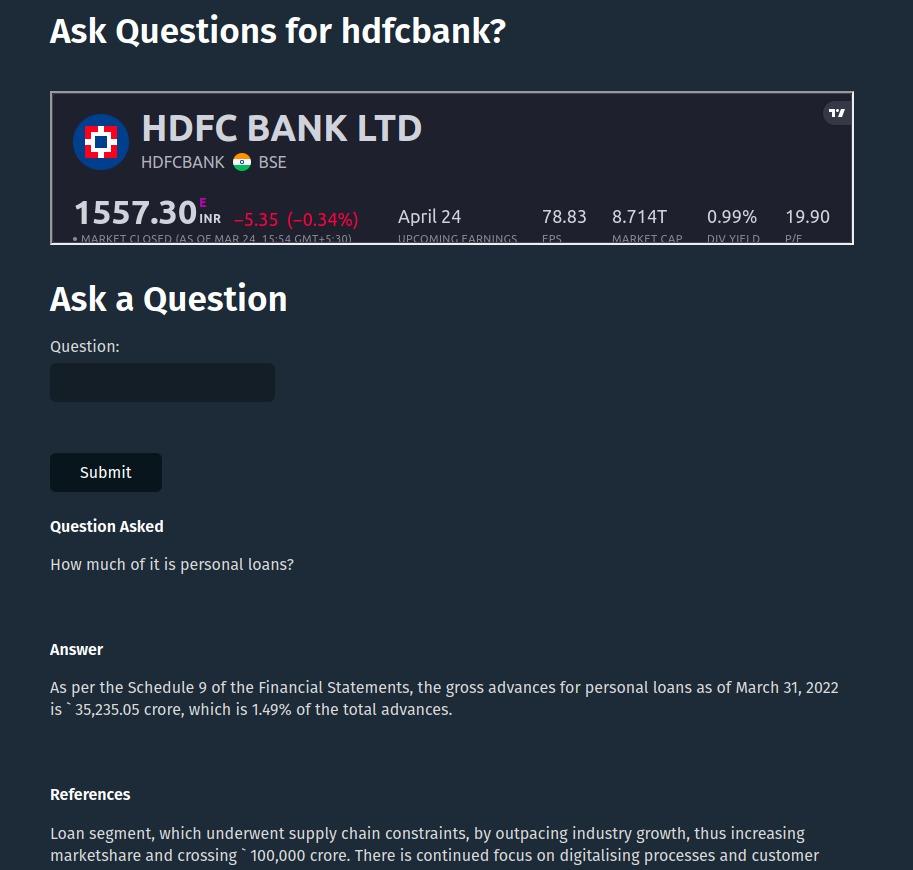
The problem FinanceGPT solves
Every company listed on the BSE publishes an annual report detailing various financial information about a company.
However this information is in the form of PDF's that are 100's of pages long that makes it difficult for any one to glean information quickly about any company. Our product FinanceGPT solves this problem by using vector embeddings which act as context for ChatGPT so that users can "ask" questions directly without having to go through long documents.
Challenges we ran into
We faced problems while setting up the API routes. The API recieved the request but did not give the desired output, leading us to rewrite the entire API using Flask instead of FastAPI. A great challenge was generating the vector embeddings and storing them. Vector embeddings allow us to provide context to ChatGPT while reducing the token count. Langchain provided us with excellent documentation for generating the embeddings. We used FAISS (Facebook AI Similarity Search) to store the large amount of embeddings in the RAM of a cloud machine without having to set up a seperate database, saving time and reducing complexity.